Behavioral Cloning¶
Paper |
Model-Free Imitation Learning with Policy Optimization [1] |
Framework(s) |

PyTorch¶ |
API Reference |
|
Code |
|
Examples |
Behavioral cloning is a simple immitation learning algorithm which maxmizes the likelhood of an expert demonstration’s actions under the apprentice policy using direct policy optimization. Garage’s implementation may use either a policy or dataset as the expert.
Default Parameters¶
policy_optimizer = torch.optim.Adam
policy_lr = 1e-3
loss = 'log_prob'
batch_size = 1000
Examples¶
bc_point¶
#!/usr/bin/env python3
"""Example of using Behavioral Cloning."""
import click
import numpy as np
from garage import wrap_experiment
from garage.envs import PointEnv
from garage.torch.algos import BC
from garage.torch.policies import GaussianMLPPolicy, Policy
from garage.trainer import Trainer
class OptimalPolicy(Policy):
"""Optimal policy for PointEnv.
Args:
env_spec (EnvSpec): The environment spec.
goal (np.ndarray): The goal location of the environment.
"""
# No forward method
# pylint: disable=abstract-method
def __init__(self, env_spec, goal):
super().__init__(env_spec, 'OptimalPolicy')
self.goal = goal
def get_action(self, observation):
"""Get action given observation.
Args:
observation (np.ndarray): Observation from PointEnv. Should have
length at least 2.
Returns:
tuple:
* np.ndarray: Optimal action in the environment. Has length 2.
* dict[str, np.ndarray]: Agent info (empty).
"""
return self.goal - observation[:2], {}
def get_actions(self, observations):
"""Get actions given observations.
Args:
observations (np.ndarray): Observations from the environment.
Has shape :math:`(B, O)`, where :math:`B` is the batch
dimension and :math:`O` is the observation dimensionality (at
least 2).
Returns:
tuple:
* np.ndarray: Batch of optimal actions.
Has shape :math:`(B, 2)`, where :math:`B` is the batch
dimension.
Optimal action in the environment.
* dict[str, np.ndarray]: Agent info (empty).
"""
return (self.goal[np.newaxis, :].repeat(len(observations), axis=0) -
observations[:, :2]), {}
@click.command()
@click.option('--loss', type=str, default='log_prob')
@wrap_experiment
def bc_point(ctxt=None, loss='log_prob'):
"""Run Behavioral Cloning on garage.envs.PointEnv.
Args:
ctxt (ExperimentContext): Provided by wrap_experiment.
loss (str): Either 'log_prob' or 'mse'
"""
trainer = Trainer(ctxt)
goal = np.array([1., 1.])
env = PointEnv(goal=goal, max_episode_length=200)
expert = OptimalPolicy(env.spec, goal=goal)
policy = GaussianMLPPolicy(env.spec, [8, 8])
batch_size = 1000
algo = BC(env.spec,
policy,
batch_size=batch_size,
source=expert,
policy_lr=1e-2,
loss=loss)
trainer.setup(algo, env)
trainer.train(100, batch_size=batch_size)
bc_point()
bc_point_deterministic_policy¶
Experiment Results¶
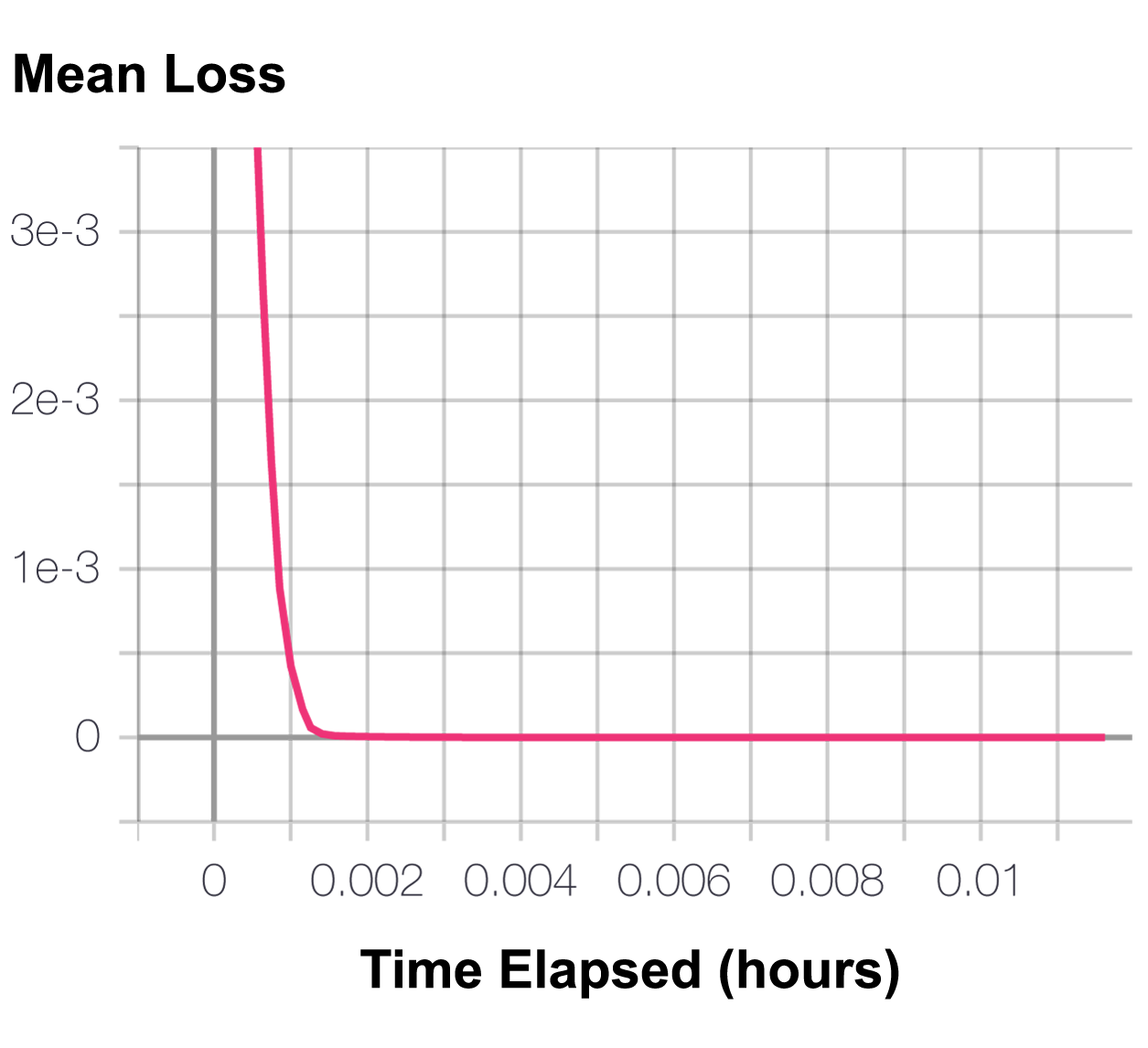 BC Mean Loss
BC Mean Loss  BC Mean Loss
BC Mean Loss
#!/usr/bin/env python3
"""Example of using Behavioral Cloning."""
import numpy as np
from garage import wrap_experiment
from garage.envs import PointEnv
from garage.torch.algos import BC
from garage.torch.policies import DeterministicMLPPolicy, Policy
from garage.trainer import Trainer
class OptimalPolicy(Policy):
"""Optimal policy for PointEnv.
Args:
env_spec (EnvSpec): The environment spec.
goal (np.ndarray): The goal location of the environment.
"""
# No forward method
# pylint: disable=abstract-method
def __init__(self, env_spec, goal):
super().__init__(env_spec, 'OptimalPolicy')
self.goal = goal
def get_action(self, observation):
"""Get action given observation.
Args:
observation (np.ndarray): Observation from PointEnv. Should have
length at least 2.
Returns:
tuple:
* np.ndarray: Optimal action in the environment. Has length 2.
* dict[str, np.ndarray]: Agent info (empty).
"""
return self.goal - observation[:2], {}
def get_actions(self, observations):
"""Get actions given observations.
Args:
observations (np.ndarray): Observations from the environment.
Has shape :math:`(B, O)`, where :math:`B` is the batch
dimension and :math:`O` is the observation dimensionality (at
least 2).
Returns:
tuple:
* np.ndarray: Batch of optimal actions.
Has shape :math:`(B, 2)`, where :math:`B` is the batch
dimension.
Optimal action in the environment.
* dict[str, np.ndarray]: Agent info (empty).
"""
return (self.goal[np.newaxis, :].repeat(len(observations), axis=0) -
observations[:, :2]), {}
@wrap_experiment
def bc_point(ctxt=None):
"""Run Behavioral Cloning on garage.envs.PointEnv.
Args:
ctxt (ExperimentContext): Provided by wrap_experiment.
"""
trainer = Trainer(ctxt)
goal = np.array([1., 1.])
env = PointEnv(goal=goal, max_episode_length=200)
expert = OptimalPolicy(env.spec, goal=goal)
policy = DeterministicMLPPolicy(env.spec, hidden_sizes=[8, 8])
batch_size = 1000
algo = BC(env.spec,
policy,
batch_size=batch_size,
source=expert,
policy_lr=1e-2,
loss='mse')
trainer.setup(algo, env)
trainer.train(100, batch_size=batch_size)
bc_point()
References¶
- 1
Jonathan Ho, Jayesh Gupta, and Stefano Ermon. Model-free imitation learning with policy optimization. In International Conference on Machine Learning, 2760–2769. 2016. URL: https://arxiv.org/abs/1605.08478.
This page was authored by Iris Liu (@irisliucy) with contributions from Ryan Julian (@ryanjulian).