Twin Delayed Deep Deterministic (TD3)¶
Paper |
Addressing Function Approximation Error in Actor-Critic Methods [1] |
|
Framework(s) |

TensorFlow¶ |

PyTorch¶ |
API Reference |
||
Code |
||
Examples |
||
Benchmarks |
||
Twin Delayed Deep Deterministic (TD3) is an alogrithm motivated by Double Q-learning and built by taking the minimum value between two critic networks to prevent the overestimation of the value function. Garage’s implementation is based on the paper’s approach, which includes clipped Double Q-learning, delayed update of target and policy networks as well as target policy smoothing.
Default Parameters¶
target_update_tau=0.01,
policy_lr=1e-4,
qf_lr=1e-3,
discount=0.99,
exploration_policy_sigma=0.2,
exploration_policy_clip=0.5,
actor_update_period=2,
Examples¶
td3_pendulum_tf¶
#!/usr/bin/env python3
"""This is an example to train a task with TD3 algorithm.
Here, we create a gym environment InvertedDoublePendulum
and use a TD3 with 1M steps.
Results:
AverageReturn: 250
RiseTime: epoch 499
"""
import tensorflow as tf
from garage import wrap_experiment
from garage.envs import GymEnv
from garage.experiment.deterministic import set_seed
from garage.np.exploration_policies import AddGaussianNoise
from garage.replay_buffer import PathBuffer
from garage.tf.algos import TD3
from garage.tf.policies import ContinuousMLPPolicy
from garage.tf.q_functions import ContinuousMLPQFunction
from garage.trainer import TFTrainer
@wrap_experiment(snapshot_mode='last')
def td3_pendulum(ctxt=None, seed=1):
"""Wrap TD3 training task in the run_task function.
Args:
ctxt (garage.experiment.ExperimentContext): The experiment
configuration used by Trainer to create the snapshotter.
seed (int): Used to seed the random number generator to produce
determinism.
"""
set_seed(seed)
with TFTrainer(ctxt) as trainer:
n_epochs = 500
steps_per_epoch = 20
sampler_batch_size = 250
num_timesteps = n_epochs * steps_per_epoch * sampler_batch_size
env = GymEnv('InvertedDoublePendulum-v2')
policy = ContinuousMLPPolicy(env_spec=env.spec,
hidden_sizes=[400, 300],
hidden_nonlinearity=tf.nn.relu,
output_nonlinearity=tf.nn.tanh)
exploration_policy = AddGaussianNoise(env.spec,
policy,
total_timesteps=num_timesteps,
max_sigma=0.1,
min_sigma=0.1)
qf = ContinuousMLPQFunction(name='ContinuousMLPQFunction',
env_spec=env.spec,
hidden_sizes=[400, 300],
action_merge_layer=0,
hidden_nonlinearity=tf.nn.relu)
qf2 = ContinuousMLPQFunction(name='ContinuousMLPQFunction2',
env_spec=env.spec,
hidden_sizes=[400, 300],
action_merge_layer=0,
hidden_nonlinearity=tf.nn.relu)
replay_buffer = PathBuffer(capacity_in_transitions=int(1e6))
td3 = TD3(env_spec=env.spec,
policy=policy,
policy_lr=1e-4,
qf_lr=1e-3,
qf=qf,
qf2=qf2,
replay_buffer=replay_buffer,
target_update_tau=1e-2,
steps_per_epoch=steps_per_epoch,
n_train_steps=1,
discount=0.99,
buffer_batch_size=100,
min_buffer_size=1e4,
exploration_policy=exploration_policy,
policy_optimizer=tf.compat.v1.train.AdamOptimizer,
qf_optimizer=tf.compat.v1.train.AdamOptimizer)
trainer.setup(td3, env)
trainer.train(n_epochs=n_epochs, batch_size=sampler_batch_size)
td3_pendulum(seed=1)
Benchmarks¶
Benchmarks Results¶
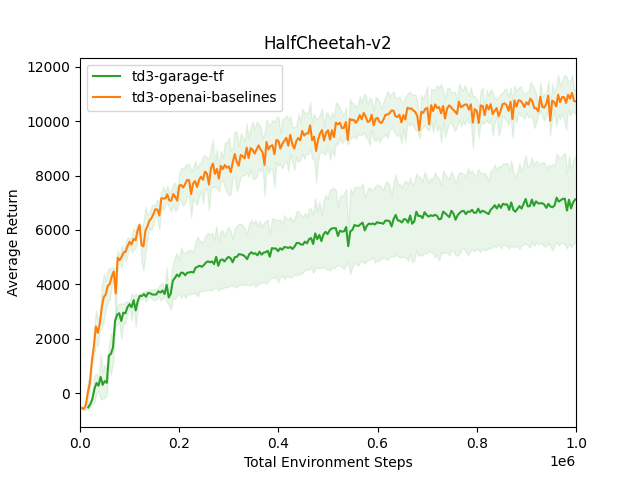 TD3 TF HalfCheetah-v2
TD3 TF HalfCheetah-v2 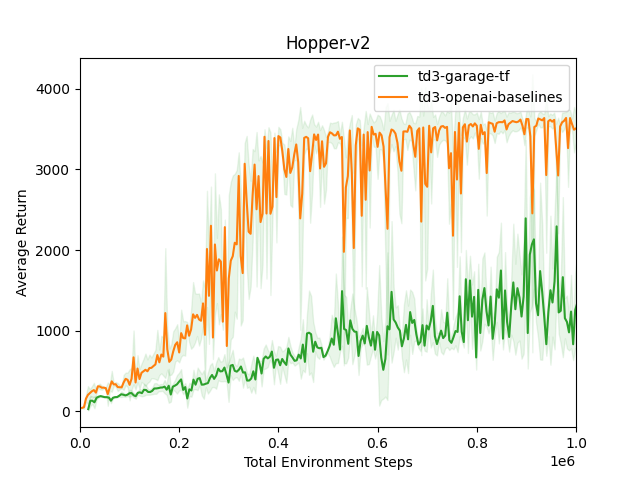 TD3 TF Hopper-v2
TD3 TF Hopper-v2
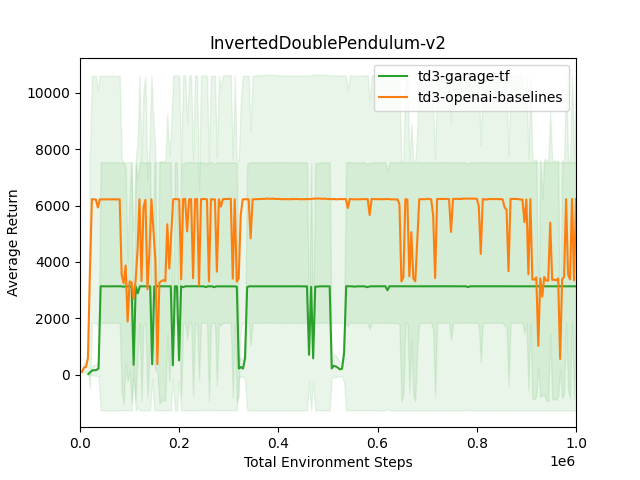 TD3 TF InvertedDoublePendulum-v2
TD3 TF InvertedDoublePendulum-v2 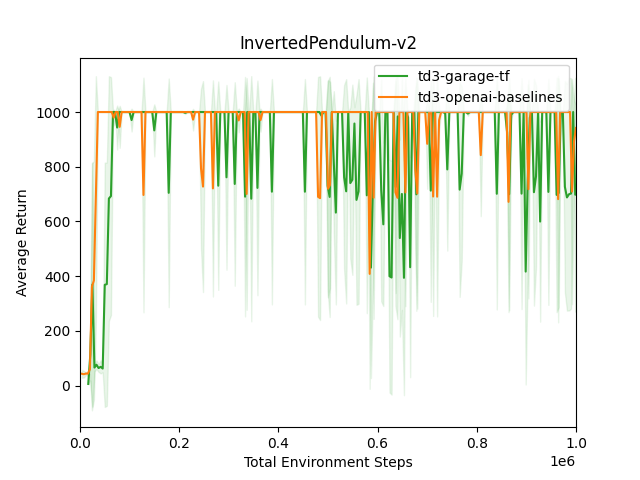 TD3 TF InvertedPendulum-v2
TD3 TF InvertedPendulum-v2
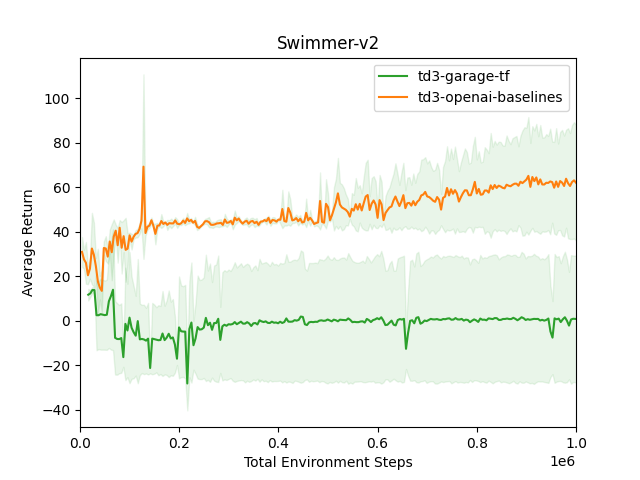 TD3 TF Swimmer-v2
TD3 TF Swimmer-v2
td3_garage_tf¶
"""A regression test for automatic benchmarking garage-TensorFlow-TD3."""
import tensorflow as tf
from garage import wrap_experiment
from garage.envs import GymEnv, normalize
from garage.experiment import deterministic
from garage.np.exploration_policies import AddGaussianNoise
from garage.replay_buffer import PathBuffer
from garage.tf.algos import TD3
from garage.tf.policies import ContinuousMLPPolicy
from garage.tf.q_functions import ContinuousMLPQFunction
from garage.trainer import TFTrainer
hyper_parameters = {
'policy_lr': 1e-3,
'qf_lr': 1e-3,
'policy_hidden_sizes': [400, 300],
'qf_hidden_sizes': [400, 300],
'n_epochs': 8,
'steps_per_epoch': 20,
'n_exploration_steps': 250,
'n_train_steps': 1,
'discount': 0.99,
'tau': 0.005,
'replay_buffer_size': int(1e6),
'sigma': 0.1,
'buffer_batch_size': 100,
'min_buffer_size': int(1e4)
}
@wrap_experiment
def td3_garage_tf(ctxt, env_id, seed):
"""Create garage TensorFlow TD3 model and training.
Args:
ctxt (ExperimentContext): The experiment configuration used by
:class:`~Trainer` to create the :class:`~Snapshotter`.
env_id (str): Environment id of the task.
seed (int): Random positive integer for the trial.
"""
deterministic.set_seed(seed)
with TFTrainer(ctxt) as trainer:
num_timesteps = (hyper_parameters['n_epochs'] *
hyper_parameters['steps_per_epoch'] *
hyper_parameters['n_exploration_steps'])
env = normalize(GymEnv(env_id))
policy = ContinuousMLPPolicy(
env_spec=env.spec,
hidden_sizes=hyper_parameters['policy_hidden_sizes'],
hidden_nonlinearity=tf.nn.relu,
output_nonlinearity=tf.nn.tanh)
exploration_policy = AddGaussianNoise(
env.spec,
policy,
total_timesteps=num_timesteps,
max_sigma=hyper_parameters['sigma'],
min_sigma=hyper_parameters['sigma'])
qf = ContinuousMLPQFunction(
name='ContinuousMLPQFunction',
env_spec=env.spec,
hidden_sizes=hyper_parameters['qf_hidden_sizes'],
action_merge_layer=0,
hidden_nonlinearity=tf.nn.relu)
qf2 = ContinuousMLPQFunction(
name='ContinuousMLPQFunction2',
env_spec=env.spec,
hidden_sizes=hyper_parameters['qf_hidden_sizes'],
action_merge_layer=0,
hidden_nonlinearity=tf.nn.relu)
replay_buffer = PathBuffer(
capacity_in_transitions=hyper_parameters['replay_buffer_size'])
td3 = TD3(env.spec,
policy=policy,
qf=qf,
qf2=qf2,
replay_buffer=replay_buffer,
steps_per_epoch=hyper_parameters['steps_per_epoch'],
policy_lr=hyper_parameters['policy_lr'],
qf_lr=hyper_parameters['qf_lr'],
target_update_tau=hyper_parameters['tau'],
n_train_steps=hyper_parameters['n_train_steps'],
discount=hyper_parameters['discount'],
min_buffer_size=hyper_parameters['min_buffer_size'],
buffer_batch_size=hyper_parameters['buffer_batch_size'],
exploration_policy=exploration_policy,
policy_optimizer=tf.compat.v1.train.AdamOptimizer,
qf_optimizer=tf.compat.v1.train.AdamOptimizer)
trainer.setup(td3, env)
trainer.train(n_epochs=hyper_parameters['n_epochs'],
batch_size=hyper_parameters['n_exploration_steps'])
References¶
- 1
Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods. ArXiv, 2018. URL: https://arxiv.org/abs/1802.09477.
This page was authored by Iris Liu (@irisliucy).