Deep Q Networks (DQN)¶
Paper |
Playing Atari with Deep Reinforcement Learning. [1] |
|
Framework(s) |

PyTorch¶ |

TensorFlow¶ |
API Reference |
||
Code |
||
Examples |
||
Deep Q Networks, or simply DQN, is a staple off-policy method ontop of which many more recent algorithms were developed. It uses a learned Q function to obtain estimates for the values of each state, action pair (S,A), and selects the optimal value by simply taking the argmax of all Q values. The algorithm is most known for learning policies that perform well on a large suite of Atari games.
Supported DQN Variants¶
As of now, both the Tensorflow and PyTorch implementations support Double DQN and Dueling DQN, as well as both combined. Double DQN can be used by simply passing a flag to the algorthim:
algo = DQN(policy=policy,
double_q=True,
...)
Dueling DQN can be used by passing in a Q function with the dueling architecture to algorithm. When using the Tensorflow branch, a dueling Q function can be constructed as follows:
qf = DiscreteCNNQFunction(env_spec=env.spec,
dueling=True,
...)
See the Pong example below for a full launcher file.
In the Pytorch branch, the architecture belongs to its own class:
qf = DiscreteDuelingCNNQFunction(env_spec=env.spec,
...)
See the Atari launcher below for a full example.
Examples¶
Both the Tensorflow and PyTorch branches of garage contain several DQN examples.
Pytorch¶
The PyTorch branch provides an Atari launcher (see below) that allows you to easily run experiments from the command line like so:
# train on PongNoFrameskip-v4 for 10M steps
python examples/torch/dqn_atari.py Pong --seed 22 --n_steps 10e6
by default, all the hyperparameters stored in the hyperparams dict at the top of the launcher file, as well as the ones passed in via the command line, are stored in the variant.json file in the experiment’s directory. You can use this feature to quickly compare hyperparameters between multiple runs.
The training curves for Dueling DQN on the Atari-10M suite are included below.
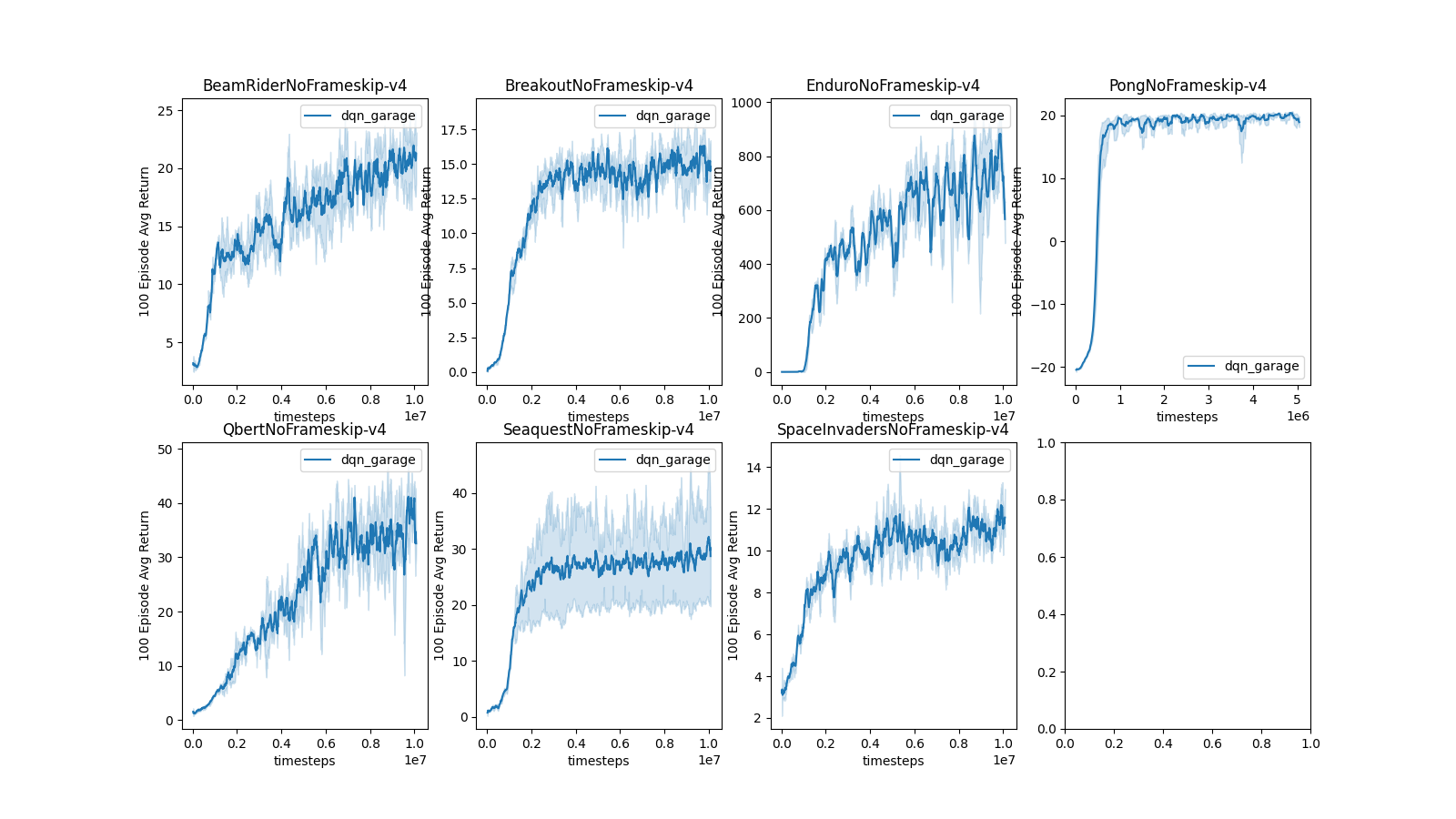 Dueling DQN on Atari 10M
Dueling DQN on Atari 10M
TF¶
References¶
- 1
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. 2013. arXiv:1312.5602.
This page was authored by Mishari Aliesa (@maliesa96).